

Check Robots.txt File
Check if your website is using a robots.txt file. When search engine robots crawl a website, they typically first access a site’s robots.txt file. Robots.txt tells Googlebot and other crawlers what is and is not allowed to be crawled on your site.
[SeoRobot]
ROBOTS.TXT TEST
Find Out the Main Opportunities of Using a Robots.txt File
User-Agent: the robot to which the following rules will be applied (for example, “Googlebot”)
Disallow: the pages you want to close for access (when beginning every new line you can include a large list of the directives alike)
Every group User-Agent / Disallow should be divided with a blank line. But non-empty strings should not occur within the group (between User-Agent and the last directive Disallow).
Hash mark (#) can be used when needed to leave commentaries in the robots.txt file for the current line. Anything mentioned after the hash mark will be ignored. When you work with robot txt file generator, this comment is applicable both for the whole line and at the end of it after the directives.
Catalogues and file names are sensible of the register: the searching system accepts «Catalog», «catalog», and «CATALOG» as different directives.
Host: is used for Yandex to point out the main mirror site. That is why if you perform 301 redirect per page to stick together two sites, there is no need to repeat the procedure for the file robots.txt (on the duplicate site). Thus, Yandex will detect the mentioned directive on the site which needs to be stuck.
Crawl-delay: you can limit the speed of your site traversing which is of great use in case of high attendance frequency on your site. Such option is enabled due to the protection of robot.txt file generator from additional problems with an extra load of your server caused by the diverse searching systems processing information on the site.
Regular phrases: to provide more flexible settings of directives, you can use two symbols mentioned below:
* (star) – signifies any sequence of symbols,
$ (dollar sign) – stands for the end of the line.
Ban on the entire site indexation
User-agent: *
Disallow: /This instruction needs to be applied when you create a new site and use subdomains to provide access to it.
Very often when working on a new site, Web developers forget to close some part of the site for indexation and, as a result, index systems process a complete copy of it. If such mistake took place, your master domain needs to undergo 301 redirect per page. Robot.txt generator can be of great use!
The following construction PERMITS to index the entire site:
User-agent: *
Disallow:
Ban on the indexation of particular folder
User-agent: Googlebot
Disallow: /no-index/
Ban on a visit to the page for the certain robot
User-agent: Googlebot
Disallow: /no-index/this-page.html
Ban on the indexation of certain type of files
User-agent: *
Disallow: /*.pdf$
To allow a visit to the determined page for the certain web robot
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page.html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.html
Website link to sitemap
User-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Peculiarities to take into consideration when using this directive if you are constantly filling your site with unique content:
- do not add a link to your site map in robots text file generator;
- choose some unstandardized name for the site map of sitemap.xml (for example, my-new-sitemap.xml and then add this link to the searching systems using webmasters);
because a great many unfair webmasters parse the content from other sites but their own and use them for their own projects.
If you don’t want some pages to undergo indexation, noindex in meta tag robots is more advisable. To implement it, you need to add the following meta tag in the section of your page:
<meta name=”robots” content=”noindex, follow”>Using this approach, you will:
- avoid indexation of certain page during the web robot’s next visit (you will not need then to delete the page manually using webmasters);
- manage to convey the link juice of your page.
Robots txt file generator serves better to close such types of pages:
- administrative pages of your site;
- search data on the site;
- pages of registration/authorization/password reset.
Which tools and how can help you check out the robots.txt file?
When you generate robots.txt, you need to verify if they contain any mistakes. The robots.txt check of the searching systems can help you cope with this task:
Sign in to account with the current site confirmed on its platform, pass to Crawl and then to robots.txt Tester.

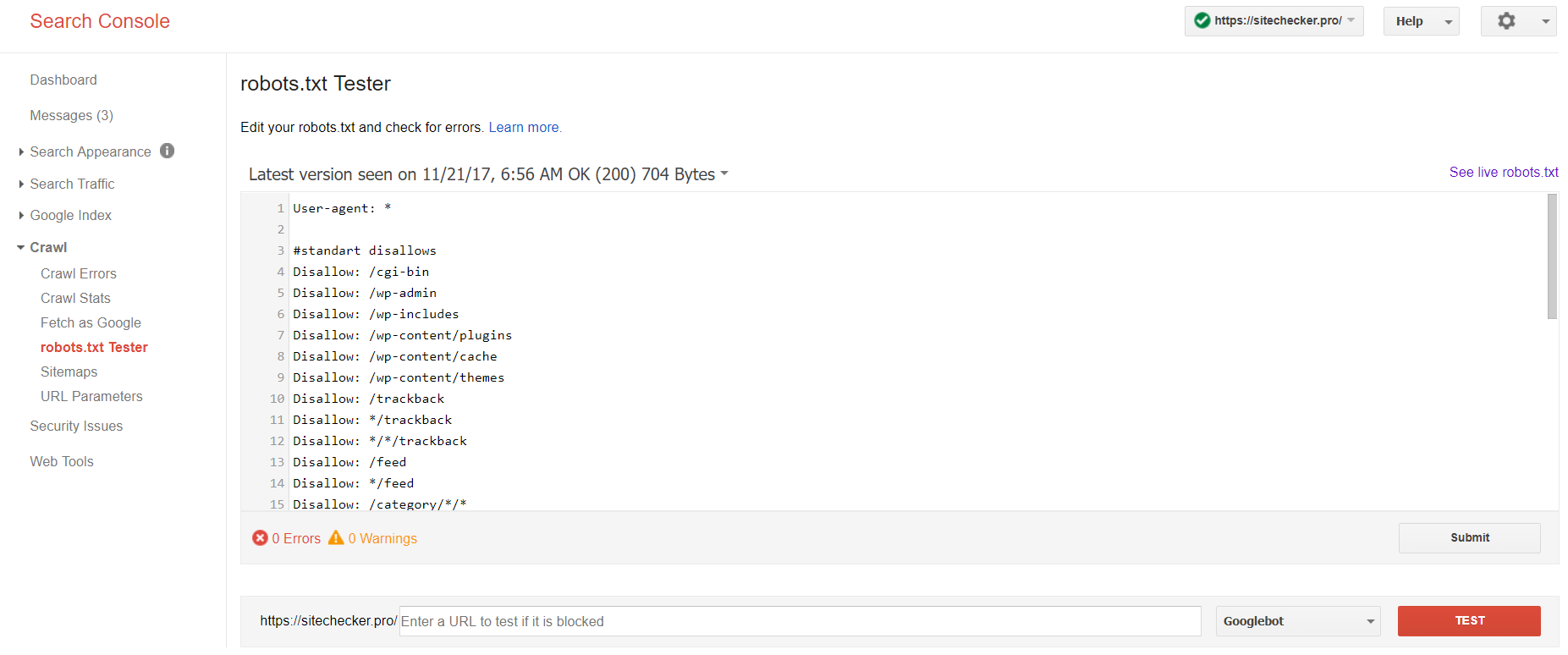

This robot txt test allows you to:
- detect all your mistakes and possible problems at once;
- check for mistakes and make the needed corrections right here to install the new file on your site without any additional verifications;
- examine whether you’ve appropriately closed the pages you’d like to avoid indexation and whether those which are supposed to undergo indexation are appropriately opened.
ROBOTS.TXT GENERATOR
Automatically Generate Robots.txt File with our Robots.txt Generator
META SEARCH
WHAT WE DO ?
PPC MANAGEMENT
TECHNICAL SEO
WEBSITE AUDITS
LOCAL SEO
WEBSITE DESIGN
SOCIAL ADVERTISING
REPUTATION MANAGEMENT
RETARGETING
FROM THE BLOG
CHECK OUR LATEST NEWS


REQUEST A QUOTE NOW
Get a FREE 15 Page Comprehensive Website Analysis Today!
OUR ADDRESS
WHERE YOU CAN FIND US
OFFICE LOCATION
8334 Pineville-Matthews Road, Suite 103-217, Charlotte, NC 28226
CALL US
EMAIL ADDRESS
WORKING HOURS
Monday – Friday 8:00 AM – 5:00 PM
 or
or 
{kind=link}